Python�ɂ��CSV�f�[�^�̎�荞��
NIDD ���������nj�����
�S���c�������A���A�ݐϕ��A�s���{����
�T���v���ɂ���f�[�^��IDWR����f�[�^�̌ܗފ����ǂɊւ��ēs���{���ʔ����������T���Ƃɂ܂Ƃ߂�ꂽCSV�t�@�C�����g�p���܂��B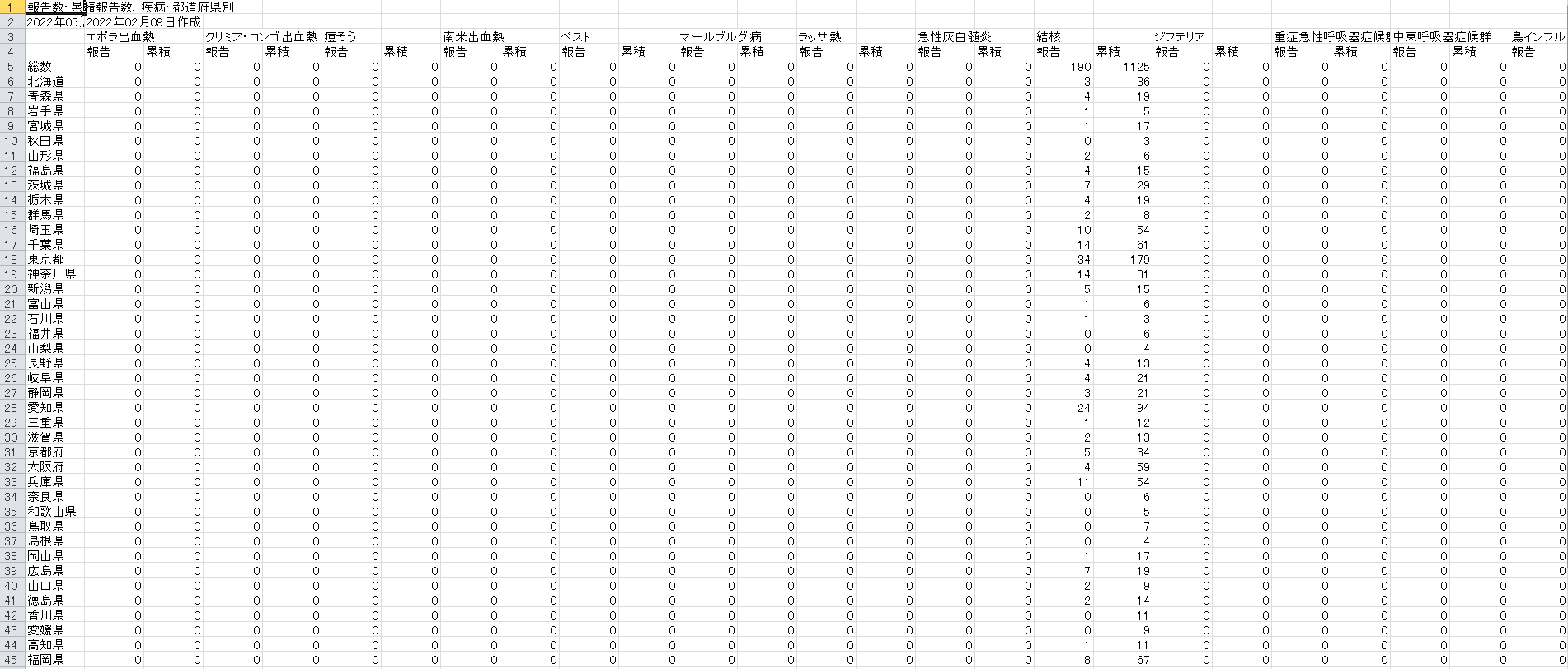
�����p�x���O�̂Ƃ���͌��ɂ����̂ł����������������Ȃ��ăf�[�^���W�Č��₷�����A����ɂ͏T���Ƃ̃f�[�^���W����@�ɂȂ�B
Jupyter Lab
�����Anaconda3��Jupyter Lab��ő����i�߂Ă������Ƃɂ��܂��B����anaconda3���jupyternotebook�Ƃ����̂�����܂������݂͊J�����~�܂��Ă���̂�jupyter lab�̂ق��ł����߂Ă����ق�������ł��傤�B
�W�vCSV�f�[�^�̃_�E�����[�h
�ȉ��̃����N����f�[�^���_�E�����[�h�B
IDWR����f�[�^ 2022�N��5�T
���̑�2022�N��6�T�����13�T�͉E�T�C�h�o�[�̈�ԉ��̃����N���\���Ă���̂ł��ꂼ����_�E�����[�h���ēK���ȃt�H���_�ɓ���Ă����܂��B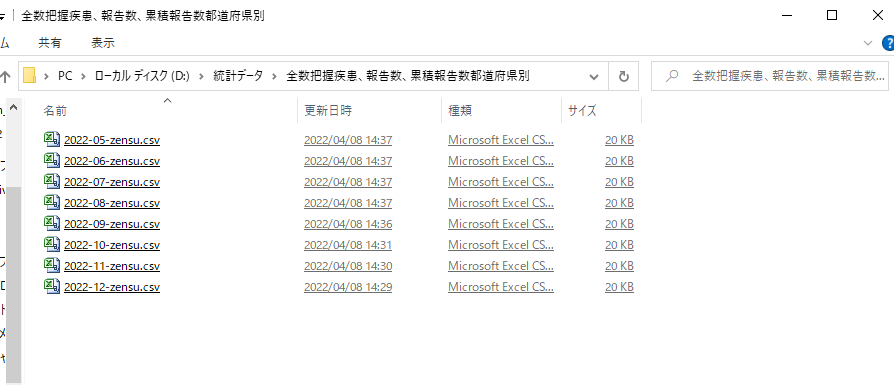
pandas�̃C���|�[�g
jupyter lab���J������K���ȃt�@�C����������pandas��glob�̃C���|�[�g�����{�B
import pandas as pd
from glob import glob
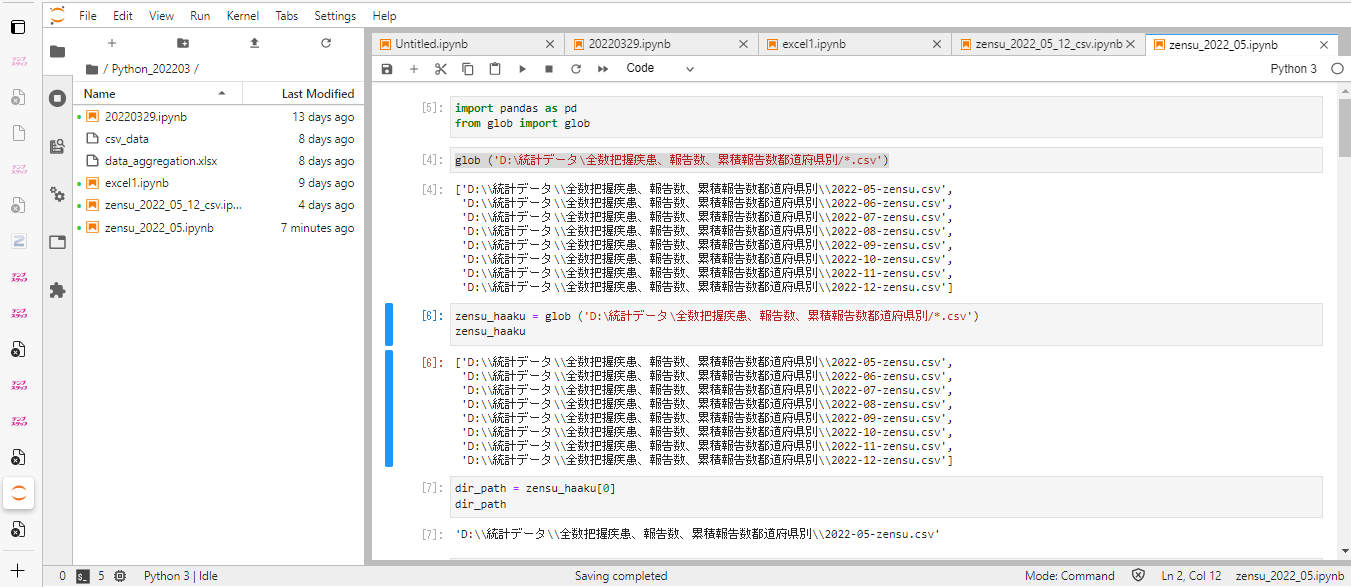
����glob�Ńt�@�C���̂���p�X���w�肵�ēǂ݂��܂���i.csv�̑O�ɂ���*�̓��C���h�J�[�h�j�B
glob ('D:\���v�f�[�^\�S���c�������A���A�ݐϕ��s���{����/*.csv')
���j�p�X�̎w�肪�킩��Ȃ��ꍇ�̓t�@�C���̂��鏊�ɒ��ړ����Ă����Ď��̂悤�Ƀp�X�����̂܂܁f��*�̊ԂɃR�s�y����B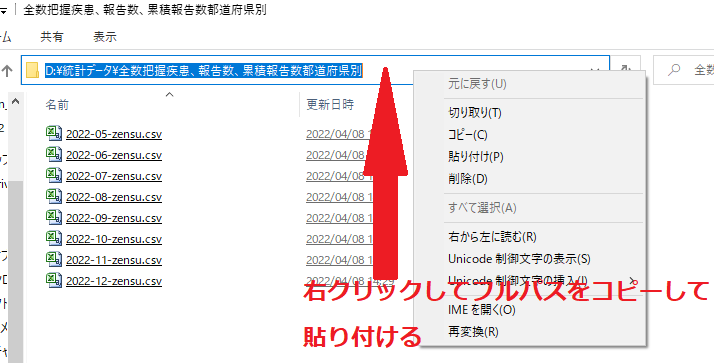
Shift + Enter�Ŏ��s�����Ď��̂悤�Ƀt�@�C����ǂݍ��܂���B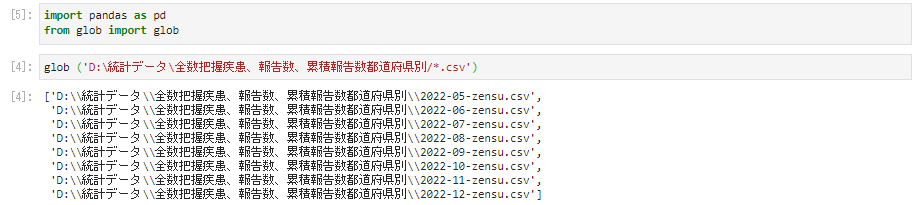
�����V����zensu_haaku�̒��ɓ����B
zensu_haaku = glob ('D:\���v�f�[�^\�S���c�������A���A�ݐϕ��s���{����/*.csv')
zensu_haaku

0�Ԗڂ̃t�@�C����dir_path�֊i�[
dir_path = zensu_haaku[0]
dir_path
���u���̒���pd.read_csv�Ńt�@�C���ǂݍ��݂�����B
df_temp = pd.read_csv(dir_path, encoding='sjis')
df_temp
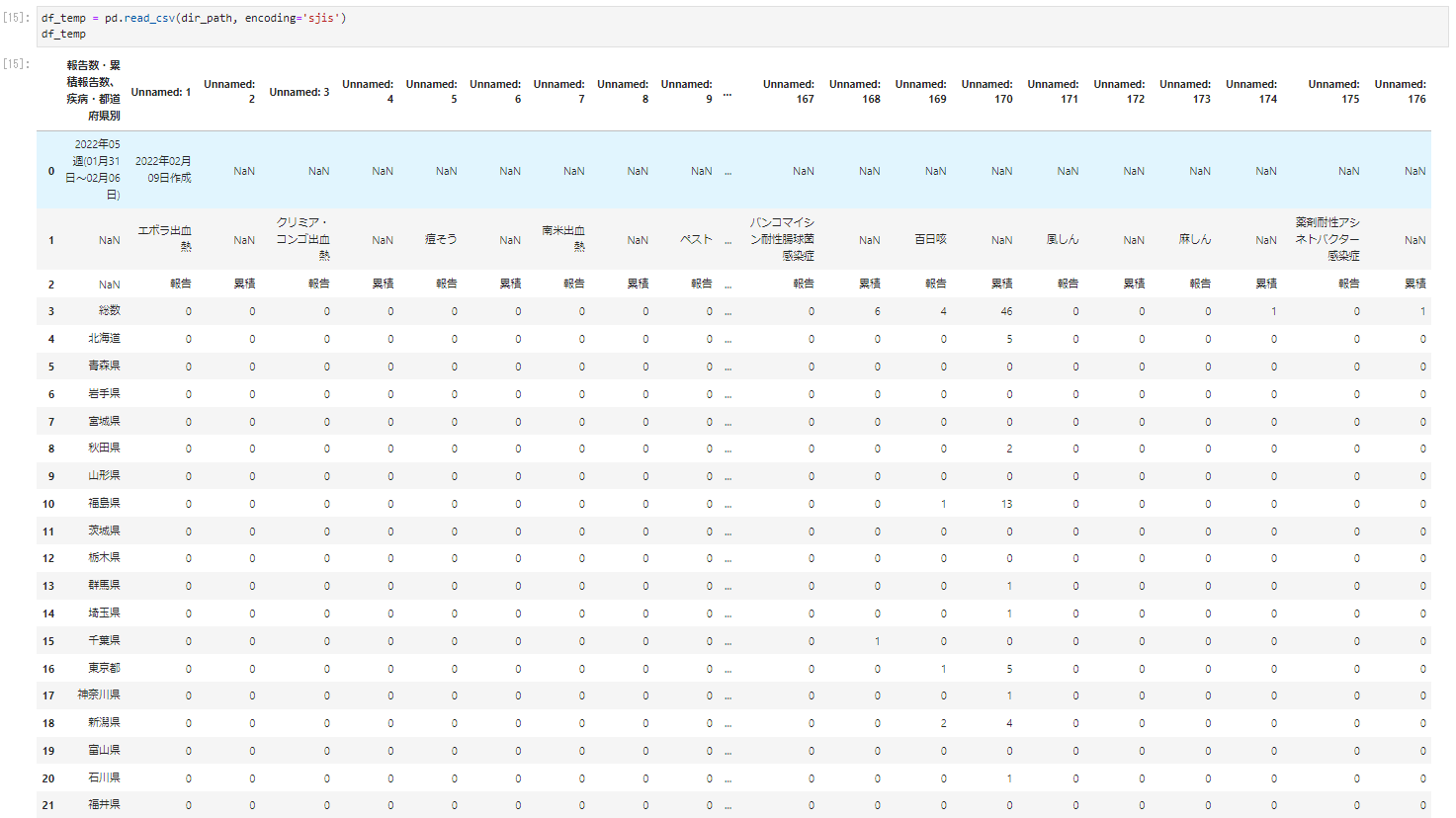
��Ƀf�[�^�̓����Ă���ӏ��̗�ƁA�Ȃ�̏ǗႩ���ʂ��邽�߂Ɏ�v�����ǖ��̂���s�����o����columns�ɓ���Ă����B
columns = df_temp.iloc[1, [0, 17, 35, 41,45,55,81,93,123,129,131,133,137,141,143,145,149,153,159,161,163,169]]
columns
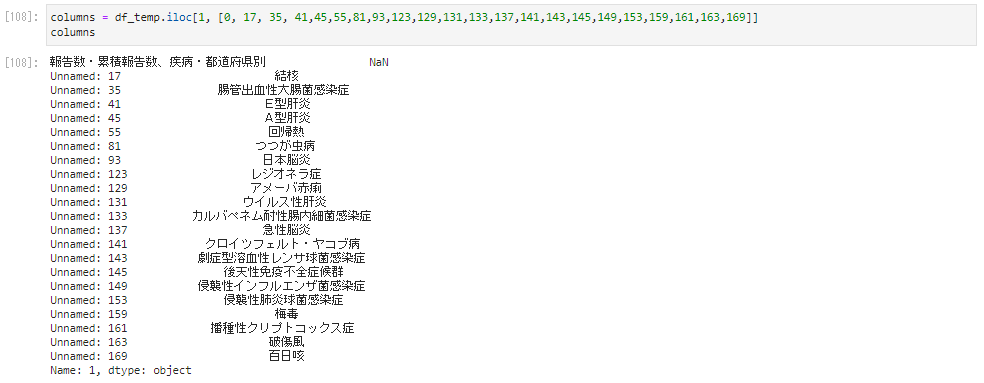
�E��Ɍ����l��NaN������̂ł������g�s���{���ʁh�Ƃ���������������܂��B
���̂悤�ɓ��́B
columns = columns.fillna('�s���{����')
columns

���Ƀf�[�^�̓����Ă���s���{���ʂ̍s�����o���Ă����B
df = df_temp.iloc[4:50, [0, 17, 35, 41,45,55,81,93,123,129,131,133,137,141,143,145,149,153,159,161,163,169]]
df
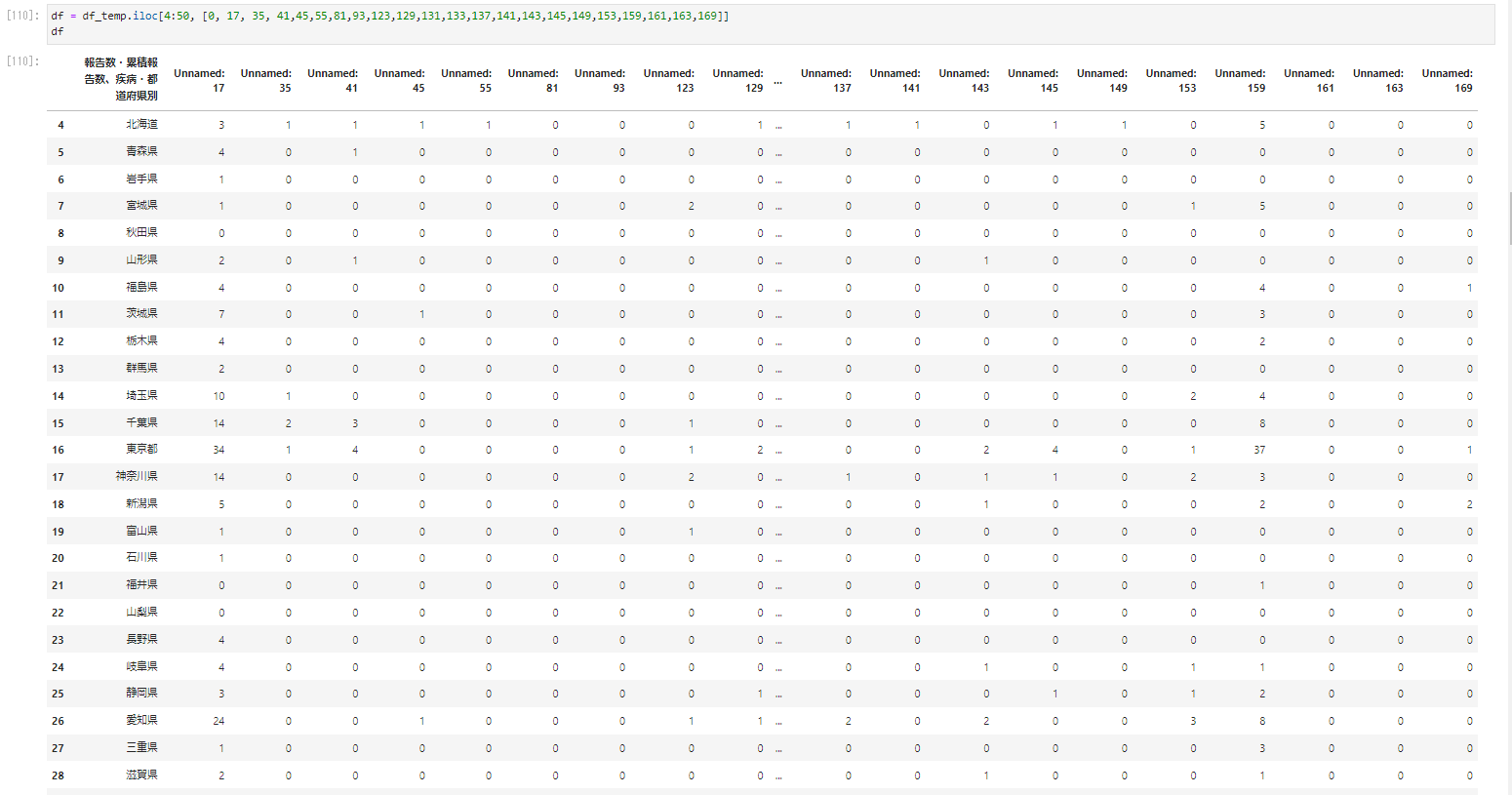
�Ȃ�̗i�a���j���킩��悤�ɐ�قǍ쐬����columns�����Ă��悤�ɂ���B
df.columns = columns
df
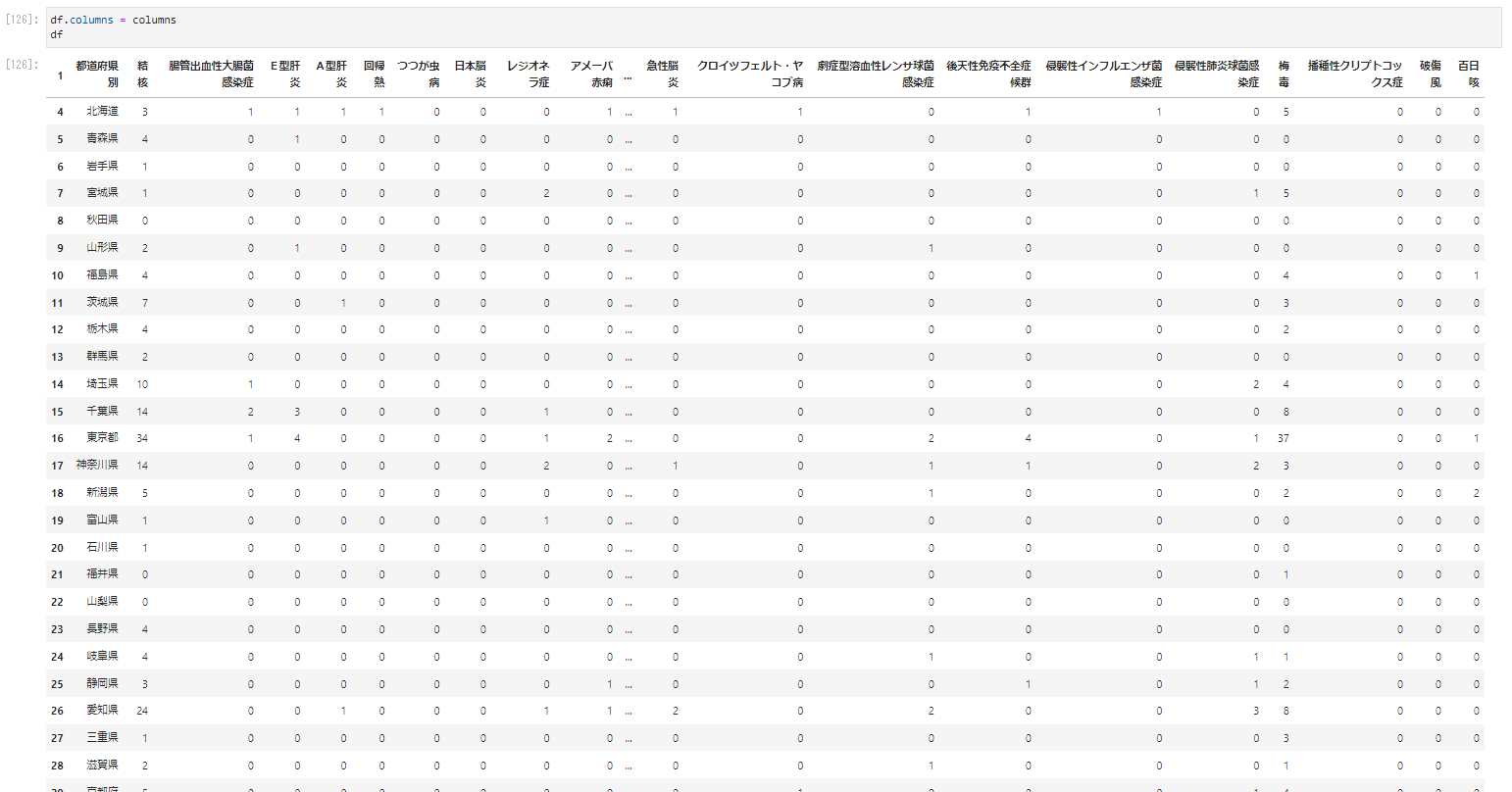
���̎����̂��̂��킩��悤�ɏT��������B
df['�T��'] = df_temp.iloc[0, 0]
df
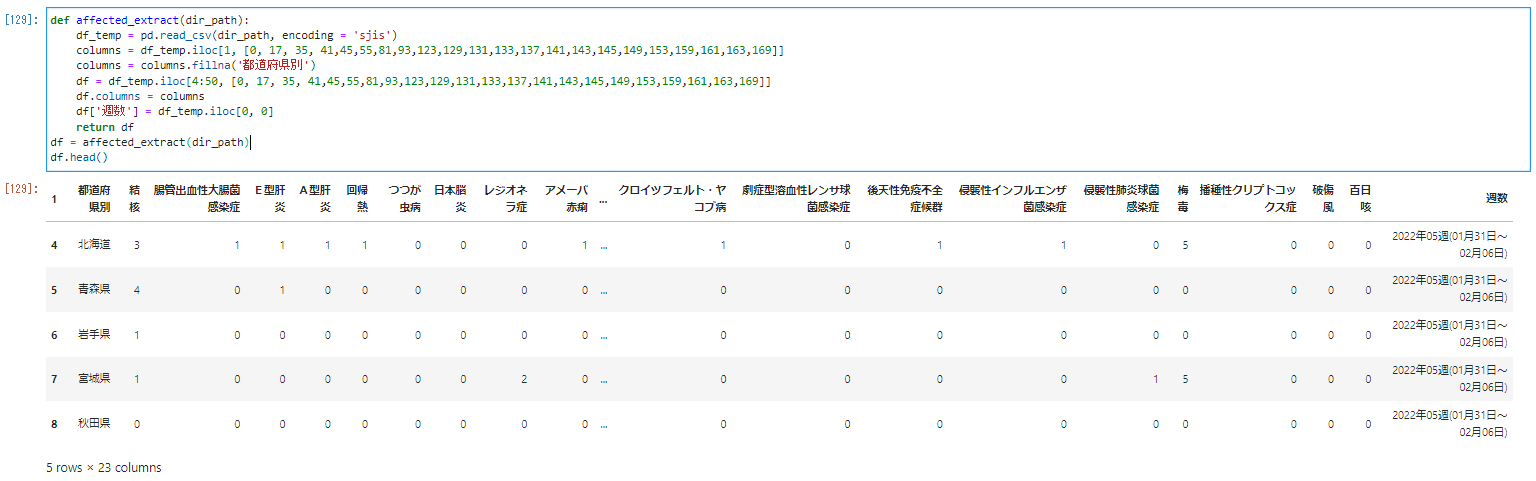
��A�̃f�[�^���o�̗�����܂Ƃ߂�affected_extract�Ƃ������ɂ܂Ƃ߂܂��B�t�@�C���̃p�X��F�������邽�߂Ɋ����̌�́i�j�̒���dir_path�Ɠ��͂��ăt�@�C������������ł��܂��B
def affected_extract(dir_path):
df_temp = pd.read_csv(dir_path, encoding = 'sjis')
columns = df_temp.iloc[1, [0, 17, 35, 41,45,55,81,93,123,129,131,133,137,141,143,145,149,153,159,161,163,169]]
columns = columns.fillna('�s���{����')
df = df_temp.iloc[4:50, [0, 17, 35, 41,45,55,81,93,123,129,131,133,137,141,143,145,149,153,159,161,163,169]]
df.columns = columns
df['�T��'] = df_temp.iloc[0, 0]
return df
df = affected_extract(dir_path)
df.head()
�f�[�^�̏W��
pd.concat
���o�̃R�[�h���o�����̂ŏT���Ƃ̃f�[�^���ЂƂ̃f�[�^�ɂ܂Ƃ߂܂��B
df = pd.DataFrame()
for dir_path in zensu_haaku:
df_temp = affected_extract(dir_path)
df = pd.concat([df, df_temp])
df
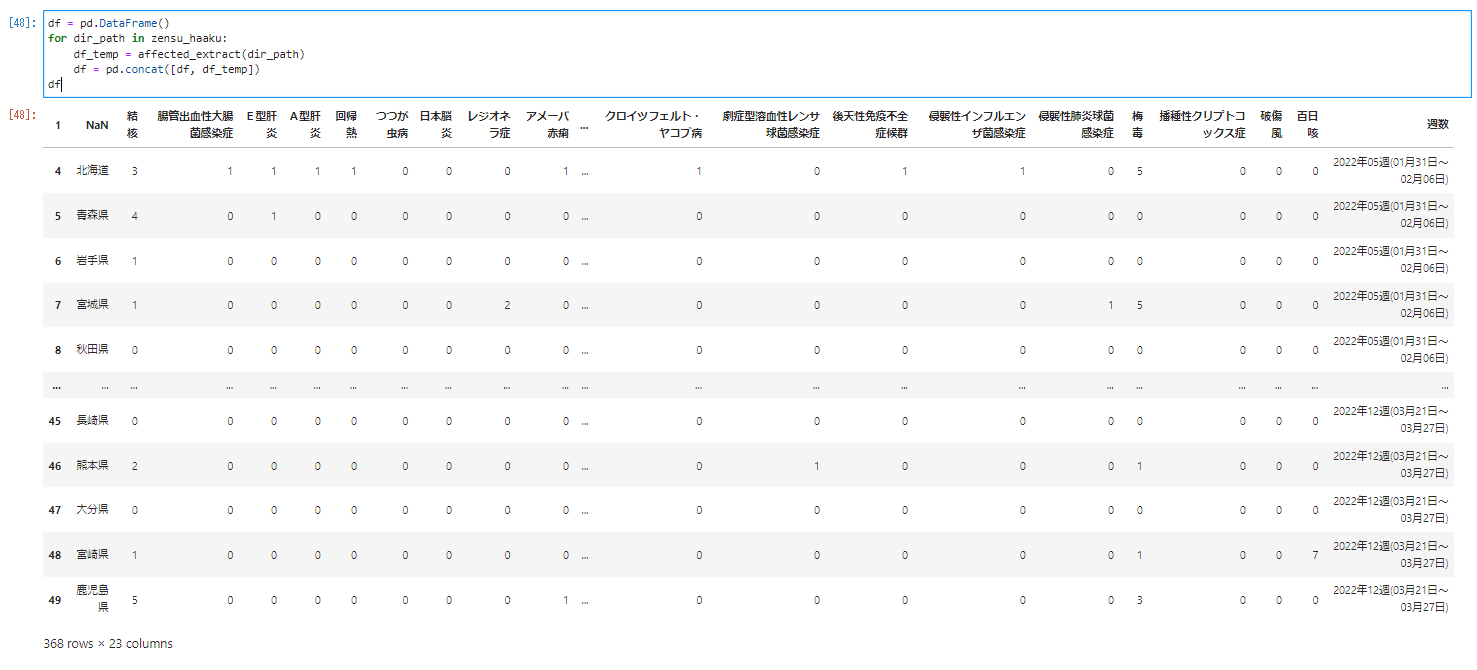
�����̍s��������킩��悤��368 rows �~ 23 columns�ƂȂ��Ă���̂Ńf�[�^���W��o���Ă��邱�Ƃ��킩��B
���̍s�Ԃ����ʂ�ɂ��邽�߂Ɉȉ��̂悤�ɓ��́B
df = df.reset_index(drop = True)
���ɂ����CSV�t�@�C���Ƃ��ďo�͂��܂��B
df.to_csv('zensu_data.csv', index = False)
���s�����zensu_haku.csv�Ƃ������O�̃t�@�C��������܂��B
������_�u���N���b�N���Ă���jupyter lab��ňȉ��̂悤�ɍ쐬���ꂽ�t�@�C�����{���o����悤�ɂȂ�܂��B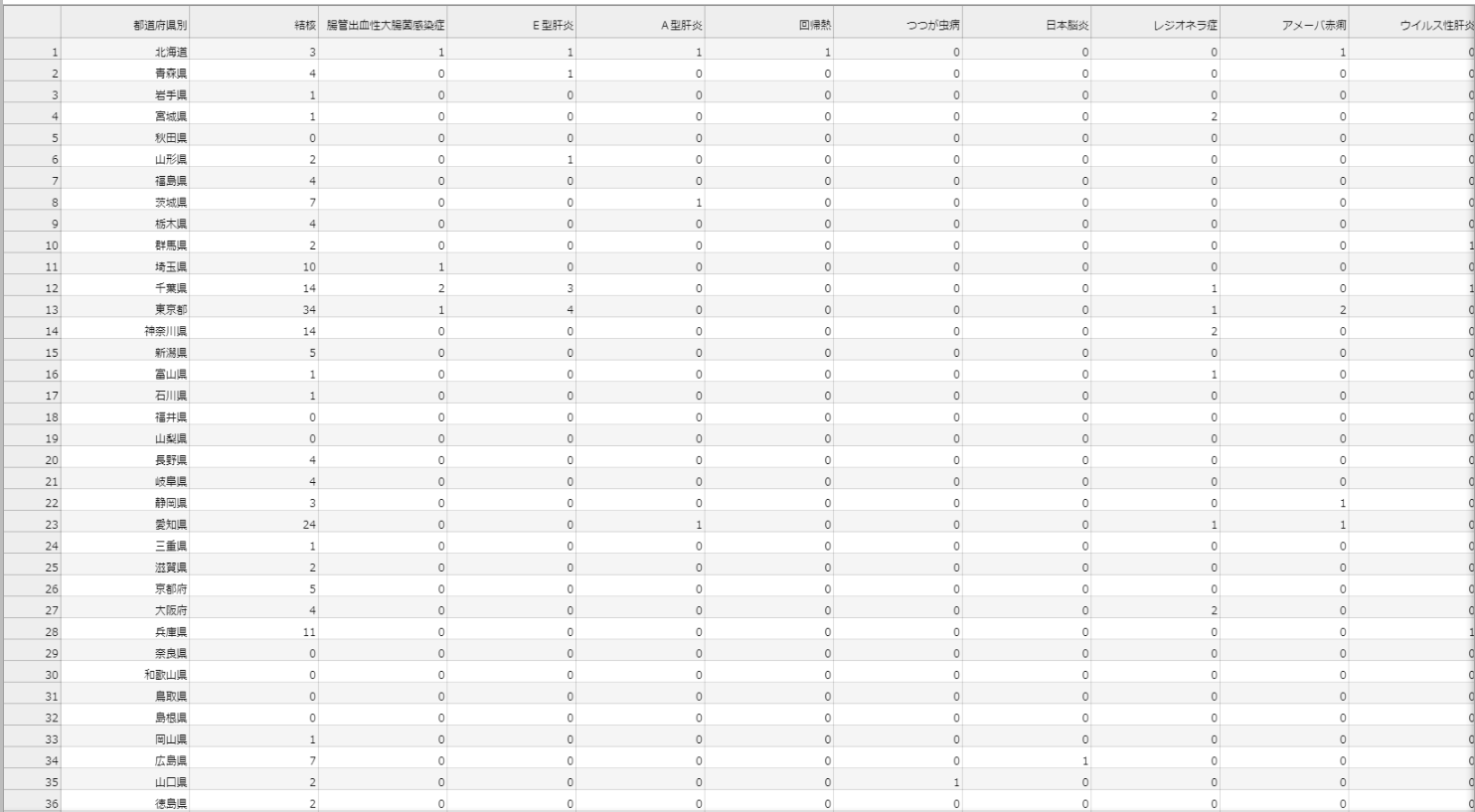
CSV�t�@�C���̕��������C��
�Ȃ��J�����g�f�B���N�g������J���ꍇ�������t�@�C�����ȉ��̂悤�ɕ����������Ă��邱�Ƃ�����܂��B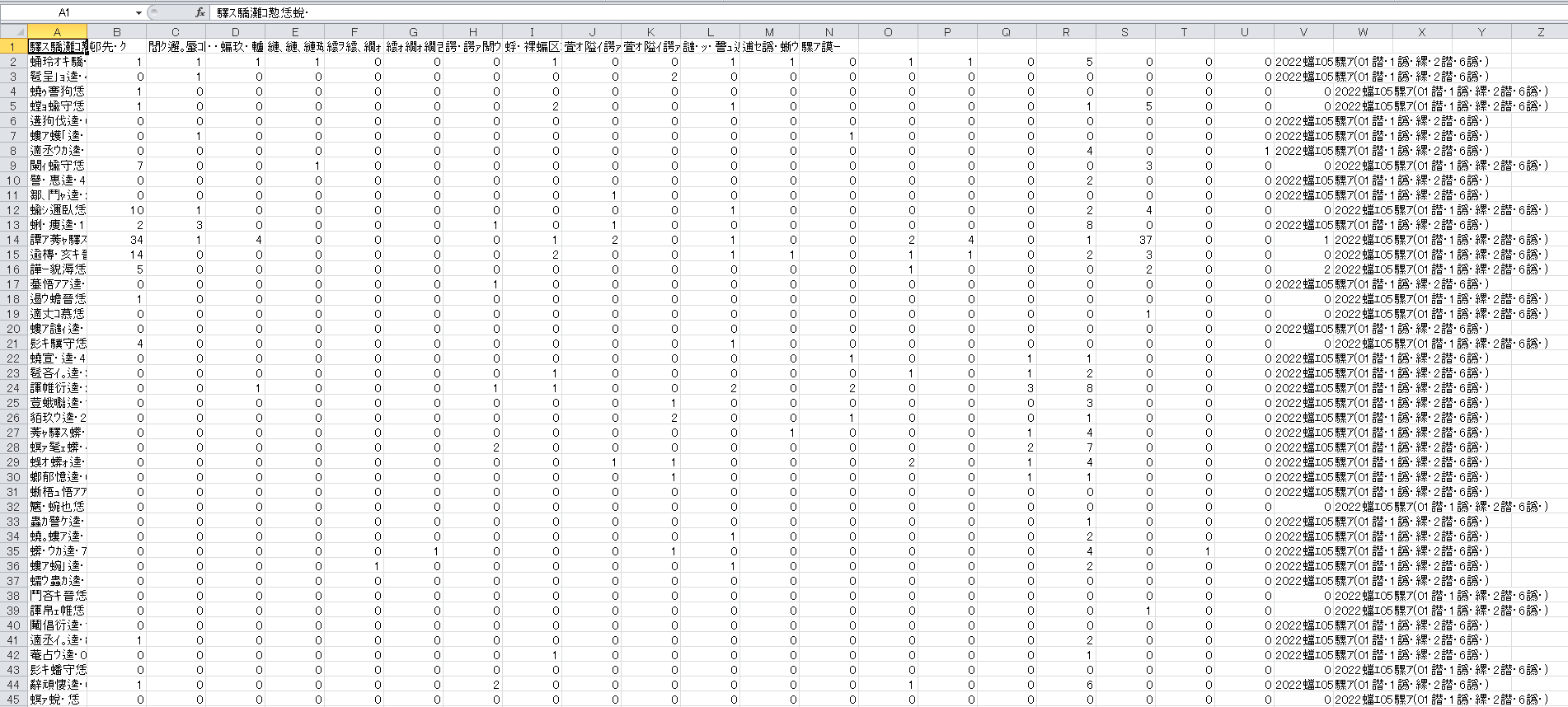
���̂悤�ɑΏ����Ă����܂��B
�܂��Ώۂ̕����������Ă���CSV���E�N���b�N���Ă�����������������ŊJ���܂��B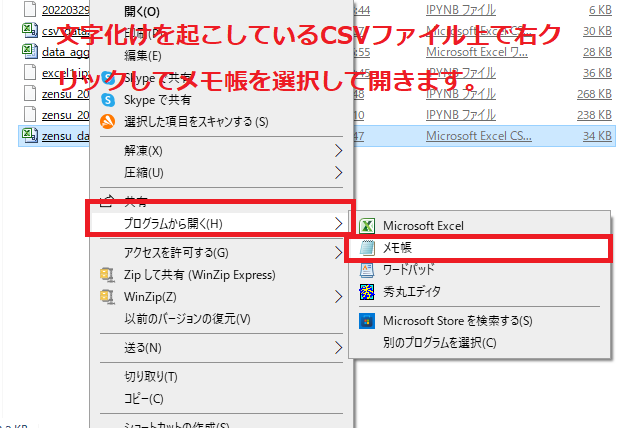
���O��t���ĕۑ����N���b�N�B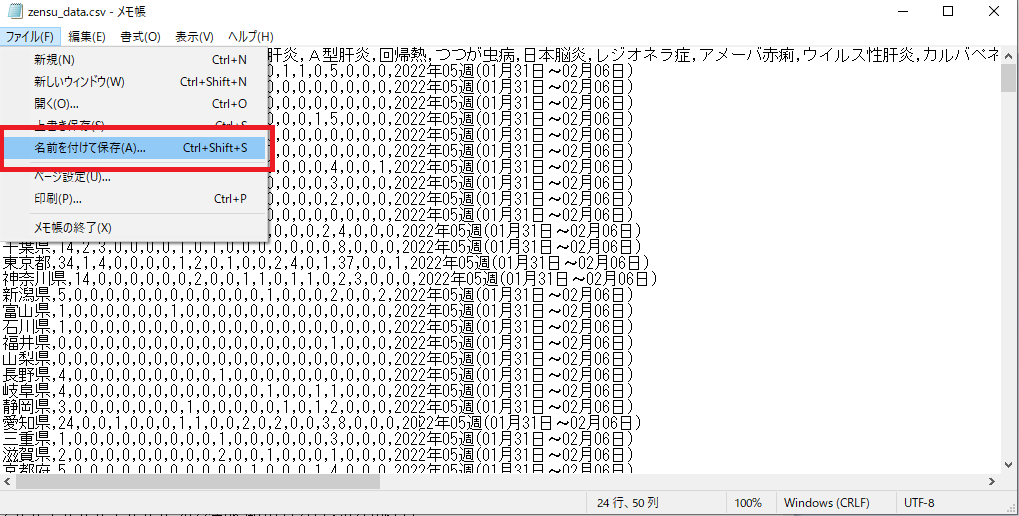
���̎������R�[�h��ANSI�ɕϊ����ď㏑���ۑ��B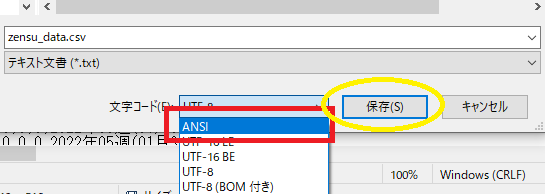
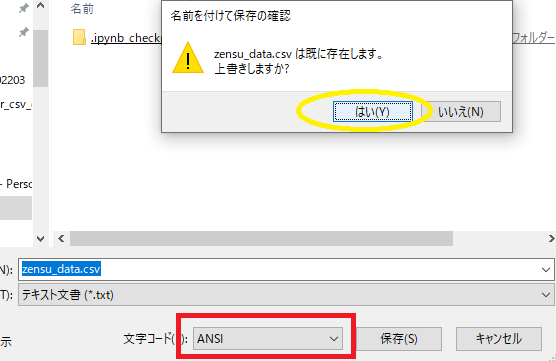
�ēx�J�������Ύ��̂悤�ɕ\�������悤�ɂȂ�܂��B
�o��
�s���{�����Ƃ̃f�[�^���o�͂���export_dir�Ƃ����t�H���_�Ɋi�[���܂��B
for i in prefectures:
df_affected = df[df['�s���{����'] == i]
df_affected.to_csv('D:\���v�f�[�^\�S���c�������A���A�ݐϕ��s���{����\export_dir' + '/' + i + '.csv')
glob ('D:\���v�f�[�^\�S���c�������A���A�ݐϕ��s���{����\export_dir/*.csv')
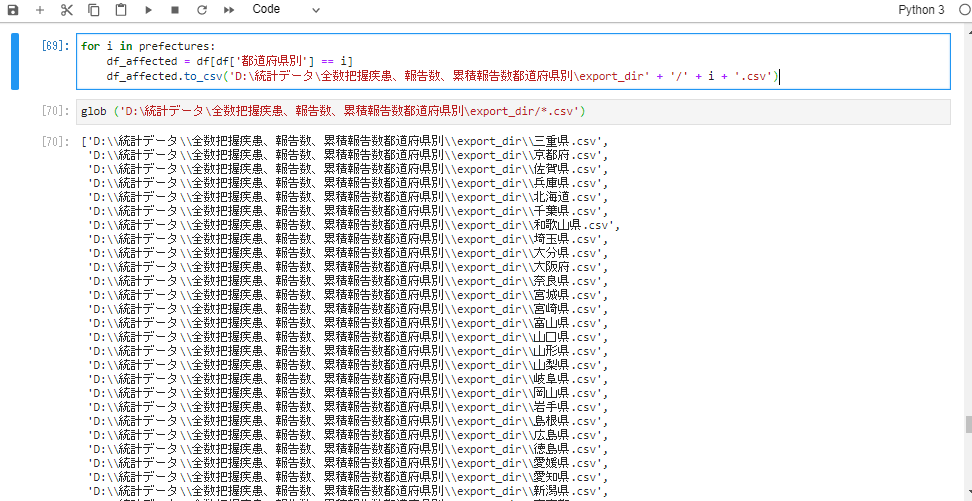
all_csv_data�֊i�[�B
all_csv_data = glob ('D:\���v�f�[�^\�S���c�������A���A�ݐϕ��s���{����\export_dir/*.csv')
all_csv_data
for���̂Ȃ���concat���g����df_all_csv_data�փf�[�^�������B
df_all_csv_data = pd.DataFrame()
for i in all_csv_data:
df_read_csv = pd.read_csv(i)
df_all_csv_data = pd.concat([df_read_csv, df_all_csv_data])
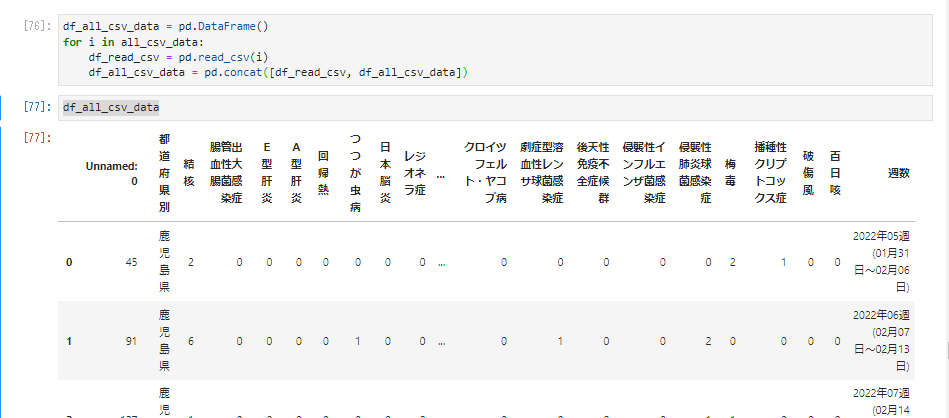
�]�v�ȗ���̂ł�������̂悤�ɂ��č폜�B
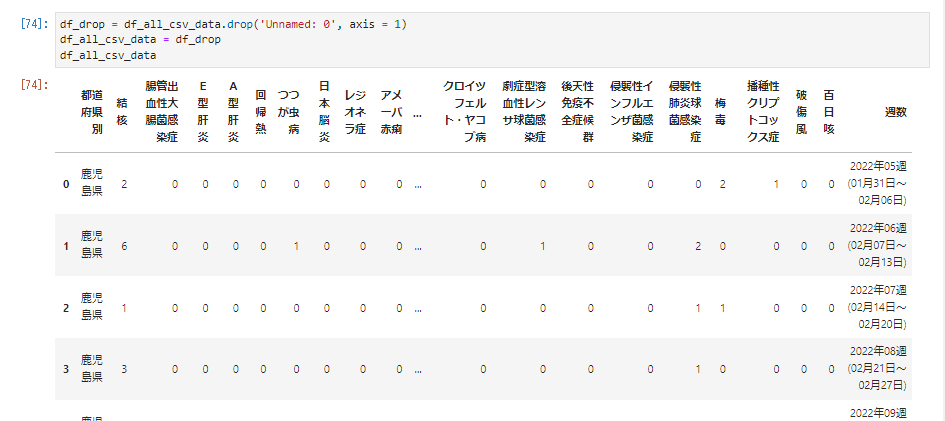
df_drop = df_all_csv_data.drop('Unnamed: 0', axis = 1)
df_all_csv_data = df_drop
df_all_csv_data
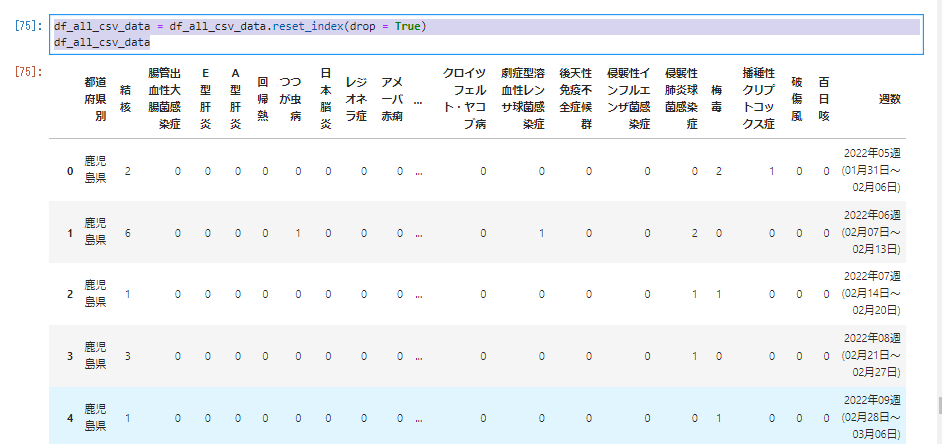
���̂悤�ɓ��͂��čs�Ԃ����Z�b�g�B
df_all_csv_data = df_all_csv_data.reset_index(drop = True)
df_all_csv_data
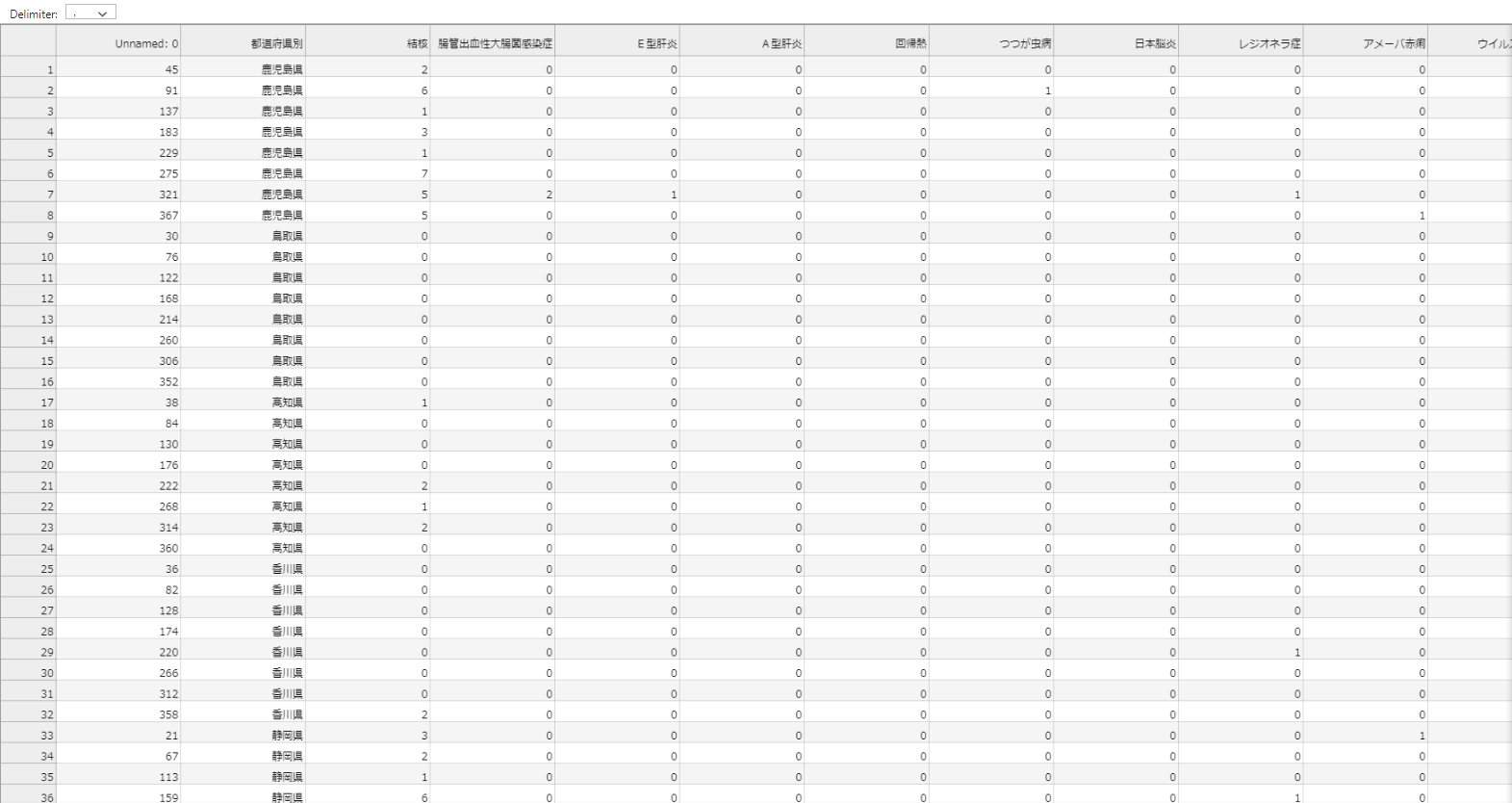
�Ō�Ɏ��̂悤�ɂ���CSV�f�[�^���o�́B
df_all_csv_data.to_csv('all_csv_data.csv', index = False)
�f�[�^�̕`��
seaborn�̓��{��Ή������Ă��Ȃ��̂ł��ꂼ��ɑΉ�����a�������̂悤�ɕ\�L�B
| ���j | tuberculosis |
|---|---|
| ���Ǐo�����咰�ۊ����� | EHEC(Enterohemorrhagic Escherichia coli infection) |
| �d�^�̉� | Hepatitis E |
| �`�^�̉� | Hepatitis A |
| ��A�M | recurrent fever |
| �����a | Tsutsugamushi disease |
| ���{�]�� | Japanese encephalitis |
| ���W�I�l���� | Legionellosis |
| �A���[�o�ԗ� | Amoebiasis |
| �E�C���X���̉� | Viral hepatitis |
| �J���o�y�l���ϐ������ۊ����� | CRE(carbapenem-resistant Enterobacteriaceae) |
| �}���]�� | Acute encephalitis |
| �N���C�c�t�F���g�E���R�u�a | CJD(Creutzfeldt-Jakob disease) |
| ���nj^�n���������T���ۊ����� | Severe invasive streptococcal disease |
| ��V���Ɖu�s�S�nj�Q | HIV |
| �N�P���C���t���G���U�ۊ����� | Invasive Haemophilus influenzae disease |
| �N�P���x�����ۊ����� | invasive pneumococcal disease |
| �~�� | Syphilis |
| �d�퐫�N���v�g�R�b�N�X�� | Cryptococcosis |
| �j���� | tetanus |
| �S���P | Whooping cough |
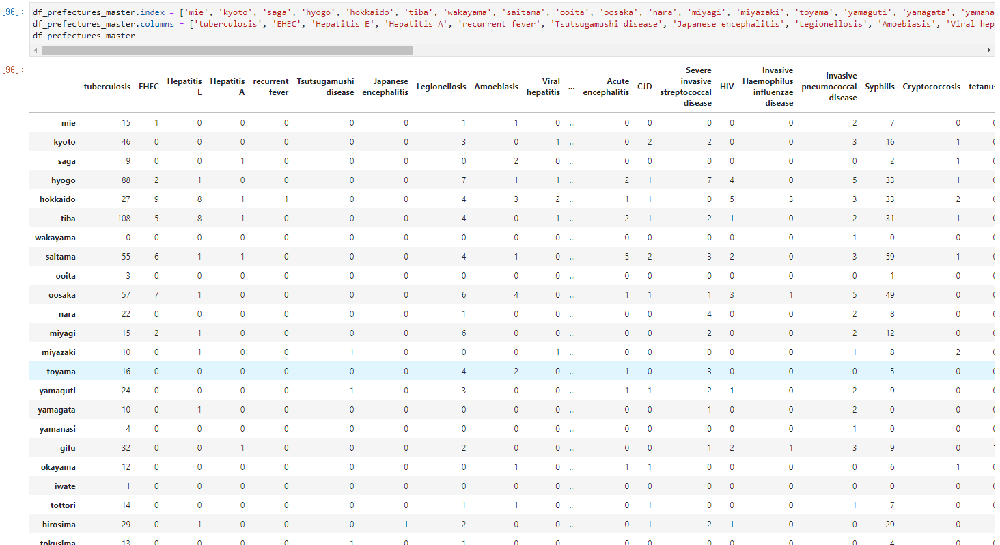
df_prefectures_master.index = ['mie', 'kyoto', 'saga', 'hyogo', 'hokkaido', 'tiba', 'wakayama', 'saitama', 'ooita', 'oosaka', 'nara', 'miyagi', 'miyazaki', 'toyama', 'yamaguti', 'yamagata', 'yamanasi', 'gifu', 'okayama', 'iwate', 'tottori', 'hirosima', 'tokusima', 'ehime', 'aiti', 'niigata', 'tokyo', 'totigi', 'siga','kumamoto', 'isikawa', 'kanagawa', 'fukui', 'fukuoka', 'fukusima', 'akita', 'gunma', 'ibaraki', 'nagasaki', 'nagano', 'aomori', 'sizuoka', 'kagawa', 'kouti', 'tottori', 'kagosima' ]
df_prefectures_master.columns = ['tuberculosis', 'EHEC', 'Hepatitis E', 'Hepatitis A', 'recurrent fever', 'Tsutsugamushi disease', 'Japanese encephalitis', 'Legionellosis', 'Amoebiasis', 'Viral hepatitis', 'CRE', 'Acute encephalitis', 'CJD', 'Severe invasive streptococcal disease', 'HIV', 'Invasive Haemophilus influenzae disease', 'invasive pneumococcal disease', 'Syphilis', 'Cryptococcosis', 'tetanus', 'Whooping cough']
df_prefectures_master
seaborn�̃C���|�[�g
���̂悤�ɓ��́B
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
�s���{�����Ƃ̎����ʊ������킩��₷�����邽�߂Ƀq�[�g�}�b�v��CSV�̐��l�f�[�^�������B
���̂悤�ɓ��́B
plt.figure(figsize = (15, 6))
cmap = sns.light_palette("#00008b", as_cmap = True)
sns.heatmap(df_prefectures_master, cmap = cmap)
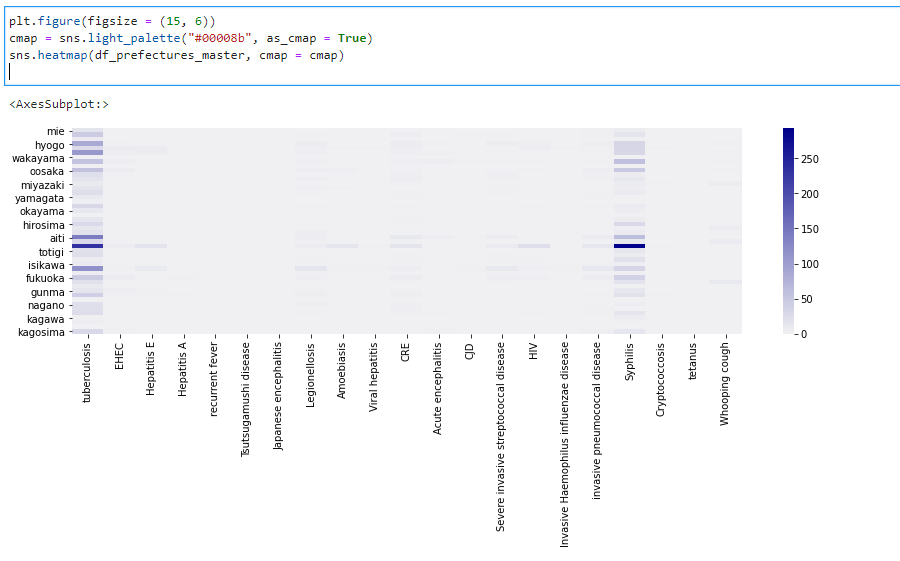
��ԍ����̎��������j�ʼnE����4�Ԗڂ̔Z���F�̗~�łɂȂ�B
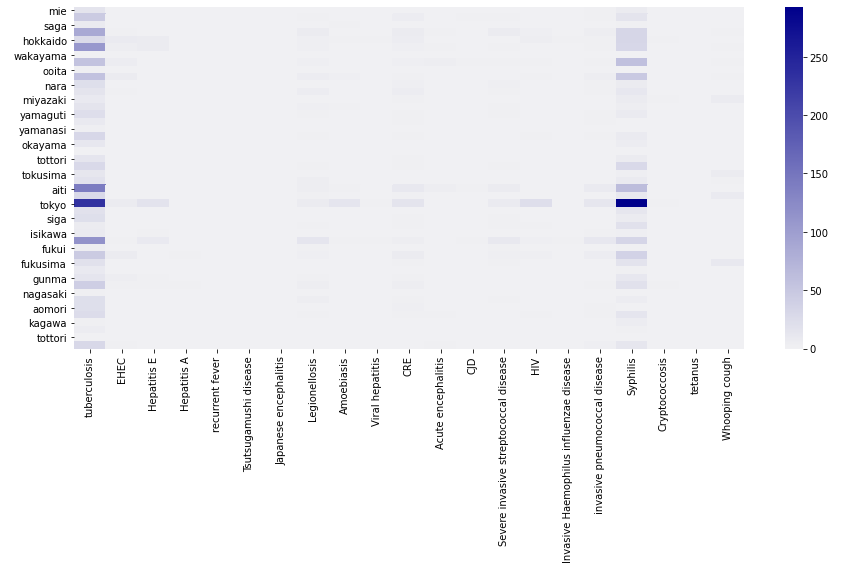
�ꕔ�̒n��������Ĕ~�ł����W�l���̍����Ƃ���ŕp�����Ă���Ƃ�킯�Ɠ����ł̌��j�Ɣ~�Ŋ����҂��������Ƃ��킩��B
Python�ɂ��CSV��荞�݊֘A�y�[�W
- Visual Studio��Python��b
- ���T�C�g�͎�ɕ����Ɋւ��鐔�w�ȂǁA���̑����ӂ��܂߂����X�������ς̃E�F�u�T�C�g�ł��B ���w����Ɋւ��Ă̎�|�Ƃ��ẮA�ʏ�̃e�L�X�g�ł͊�������Ă��܂����e�Ȃǂ��ڂ����L�q���A����ɂ͓������������̂ł͂Ȃ��A�킩��ɂ������e�������ɂ킩��₷���`���邩���ȂǁA�����������E�F�u�R���e���c�Ȃ�ł̗͂����Ƌ@�����������T�C�g�쐬�����Ƃ��Ă��܂��B
- Visual Studio��Python����낤
- ���T�C�g�͎�ɕ����Ɋւ��鐔�w�ȂǁA���̑����ӂ��܂߂����X�������ς̃E�F�u�T�C�g�ł��B ���w����Ɋւ��Ă̎�|�Ƃ��ẮA�ʏ�̃e�L�X�g�ł͊�������Ă��܂����e�Ȃǂ��ڂ����L�q���A����ɂ͓������������̂ł͂Ȃ��A�킩��ɂ������e�������ɂ킩��₷���`���邩���ȂǁA�����������E�F�u�R���e���c�Ȃ�ł̗͂����Ƌ@�����������T�C�g�쐬�����Ƃ��Ă��܂��B
- python�ɂ��3�����`��
- ���T�C�g�͎�ɕ����Ɋւ��鐔�w�ȂǁA���̑����ӂ��܂߂����X�������ς̃E�F�u�T�C�g�ł��B ���w����Ɋւ��Ă̎�|�Ƃ��ẮA�ʏ�̃e�L�X�g�ł͊�������Ă��܂����e�Ȃǂ��ڂ����L�q���A����ɂ͓������������̂ł͂Ȃ��A�킩��ɂ������e�������ɂ킩��₷���`���邩���ȂǁA�����������E�F�u�R���e���c�Ȃ�ł̗͂����Ƌ@�����������T�C�g�쐬�����Ƃ��Ă��܂��B
- python�`��
- ���T�C�g�͎�ɕ����Ɋւ��鐔�w�ȂǁA���̑����ӂ��܂߂����X�������ς̃E�F�u�T�C�g�ł��B ���w����Ɋւ��Ă̎�|�Ƃ��ẮA�ʏ�̃e�L�X�g�ł͊�������Ă��܂����e�Ȃǂ��ڂ����L�q���A����ɂ͓������������̂ł͂Ȃ��A�킩��ɂ������e�������ɂ킩��₷���`���邩���ȂǁA�����������E�F�u�R���e���c�Ȃ�ł̗͂����Ƌ@�����������T�C�g�쐬�����Ƃ��Ă��܂��B
- python�C���X�g�[��
- ���T�C�g�͎�ɕ����Ɋւ��鐔�w�ȂǁA���̑����ӂ��܂߂����X�������ς̃E�F�u�T�C�g�ł��B ���w����Ɋւ��Ă̎�|�Ƃ��ẮA�ʏ�̃e�L�X�g�ł͊�������Ă��܂����e�Ȃǂ��ڂ����L�q���A����ɂ͓������������̂ł͂Ȃ��A�킩��ɂ������e�������ɂ킩��₷���`���邩���ȂǁA�����������E�F�u�R���e���c�Ȃ�ł̗͂����Ƌ@�����������T�C�g�쐬�����Ƃ��Ă��܂��B























